Trabajando con sistemas integrados es común escuchar el término de domótica. En la clase y laboratorio hay un grupo de personas que actualmente están trabajando en realizar diferentes proyectos que están enfocados en esa área, como el control de aire acondicionado, regulación del flujo de agua y otros proyectos interesantes, por lo que decidí investigar un poco al respecto.
Domótica
Se entiende por domótica el conjunto de sistemas capaces de automatizar una vivienda, aportando servicios de gestión energética, seguridad, bienestar y comunicación, y que pueden estar integrados por medio de redes interiores y exteriores de comunicación, cableadas o inalámbricas, y cuyo control goza de cierta ubicuidad, desde dentro y fuera del hogar. Se podría definir como la integración de la tecnología en el diseño inteligente de un recinto cerrado.
La automatización de la casa puede incluir control centralizado de la luz, ventilación, calentamiento y el aire acondicionado, además de otros sistemas, para mejorar el confort, eficiencia de energía y la seguridad. También existe un tipo de domótica dedicado a las personas ancianas y discapacitadas que puede proveer una calidad de vida mejorada para las personas que de otra manera requieren de enfermeras u otro tipo de cuidado.
Un sistema como este requiere circuitos eléctricos integrados unos con otros dentro de una casa. Las técnicas empleadas incluyen no solo las mencionadas anteriormente, sino también el control de actividades domésticas como los sistemas de entretenimiento, regado de plantas, alimentación de mascotas, cambiar el ambiente para diferentes eventos, y el uso de robots domésticos.
Los dispositivos pueden ser conectados mediante una red de computadoras para permitir el control mediante una computadora personal, y pueden ser usadas remotamente a través de internet. Mediante la integración de las tecnologías de información, estos sistemas pueden comunicarse de una manera integrada lo que resulta en beneficios en la seguridad y la eficiencia de la energía.
Ya que el número de dispositivos controlables en una casa aumenta, la interconexión y comunicación se convierte en una característica conveniente y deseada. Por ejemplo, una chimenea puede enviar un mensaje de alerta cuando necesita limpieza, o un refrigerador cuando necesita reparación. Los cuartos pueden ser inteligentes y enviar señales al controlador cuando alguien entra. Si se supone que nadie debería estar en la casa y la alarma es activada, el sistema llamaría al dueño, los vecinos o a un número de emergencia.
En instalaciones simples esto puede ser tan simple como prender los focos cuando una persona entra en un cuarto. Por otro lado, en sistemas avanzados los cuartos pueden sentir no solo cuando una persona esta dentro, sino saber quien es esa persona y quizás ajustar la luz, temperatura, niveles de música o canales de televisión, tomando en cuenta el día de la semana, la hora del día y otros factores.
Otras tareas automáticas incluyen activar el aire acondicionado para ajustarlo a un modo de ahorro de energía cuando no haya personas en la casa, y volviendo al modo normal cuando una persona esta por volver. Algunos sistemas más sofisticados pueden mantener un inventario de productos, grabando su uso mediante códigos de barra, o una etiqueta RFID, y preparar una lista de compras o hasta ordenar reemplazos automáticamente.
La domótica también provee una interfaz remota para los aparatos caseros o la automatización del sistema en sí mediante una línea de teléfono, transmisión inalámbrica o el internet, para permitir el control y monitoreo mediante un smartphone o un navegador web.
Un ejemplo de monitoreo remoto en la domótica puede referirse a un detector de incendios, que detecta cuando hay una posible alerta de incendio, haciendo que todas las luces de la casa parpadeen para informar de una posible alerta de incendio. Si el la casa esta equipada con un home theatre, un sistema con automatización en casa puede apagar todos los componentes de audio y video para evitar distracciones, o para hacer un anuncio de emergencia. El sistema puede también llamar al dueño de la casa a su número de celular para alertarlo, o llamar al departamento de bomberos.
En términos de automatización de luz en la casa, es posible ahorrar energía instalando varios productos. Con funciones simples como sensores y detectores de movimiento integrados en un simple sistema, se pueden ahorrar horas de energía desperdiciada en aplicaciones residenciales y comerciales.
Arquitectura
Desde el punto de vista de donde reside la inteligencia del sistema domótico, hay varias arquitecturas diferentes:
- Arquitectura Centralizada: un controlador centralizado recibe información de múltiples sensores y, una vez procesada, genera las órdenes oportunas para los actuadores.
- Arquitectura Distribuida: toda la inteligencia del sistema está distribuida por todos los módulos sean sensores o actuadores. Suele ser típico de los sistemas de cableado en bus, o redes inalámbricas.
- Arquitectura mixta: sistemas con arquitectura descentralizada en cuanto a que disponen de varios pequeños dispositivos capaces de adquirir y procesar la información de múltiples sensores y transmitirlos al resto de dispositivos distribuidos por la vivienda, por ejemplo, aquellos sistemas basados en Zigbee y totalmente inalámbricos.
Aplicaciones
Podemos dividir las funciones o servicios que se ofrecen en cinco subgrupos:
1. Ahorro Energético
El ahorro energético es un concepto al que se puede llegar de muchas maneras. En muchos casos no es necesario sustituir los aparatos o sistemas del hogar por otros que consuman menos sino una gestión eficiente de los mismos.
- Climatización: programación y zonificación.
Gestión eléctrica:
- Racionalización de cargas eléctricas: desconexión de equipos de uso no prioritario en función del consumo eléctrico en un momento dado
- Gestión de tarifas, derivando el funcionamiento de algunos aparatos a horas de tarifa reducida
- Uso de energías renovables
2. Confort
El confort conlleva todas las actividades que se puedan llevar a cabo que mejoren el confort en una vivienda.
Iluminación:
- Apagado general de todas las luces de la vivienda
- Automatización del apagado/ encendido en cada punto de luz.
- Regulación de la iluminación según el nivel de luminosidad ambiente
- Automatización de todos los distintos sistemas/ instalaciones / equipos dotándolos de control eficiente y de fácil manejo
- Integración del portero al teléfono, o del videoportero al televisor
- Control vía Internet
- Gestión Multimedia y del ocio electrónicos
- Generación de macros y programas de forma sencilla para el usuario.
3. Seguridad
Consiste en una red de seguridad encargada de proteger tanto los bienes patrimoniales como la seguridad personal.
4. Comunicaciones
Son los sistemas o infraestructuras de comunicaciones que posee el hogar.
- Control remoto desde Internet, PC, mandos inalámbricos(smartphones, PDA con WiFi).
- Asistencia remota
- Mantenimiento remoto
- Informes de consumo y costes
- Transmisión de alarmas.
- Intercomunicaciones.
5. Accesibilidad
En la accesibilidad se incluyen las aplicaciones o instalaciones de control remoto del entorno que favorecen la autonomía personal de personas con limitaciones funcionales, o discapacidad.
La domótica aplicada a favorecer la accesibilidad es un reto ético y creativo pero sobre todo es la aplicación de la tecnología en el campo más necesario, para suplir limitaciones funcionales de las personas. El objetivo de estas tecnologías es favorecer la autonomía personal. Los destinatarios de estas tecnologías son todas las personas, ya que por enfermedad o envejecimiento, todos somos o seremos discapacitados, más pronto o más tarde.
Referencias













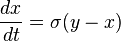

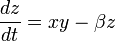
 ,
, 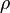 ,
,  , son los parámetros del sistema.
, son los parámetros del sistema. 





.JPG)






{kind=link}